Two-Part Primer: What Frontier AI Can Do in Cybersecurity
In early April 2026, Anthropic announced its latest model, Mythos Preview, which featured impressive cyber-offensive capabilities, and Project Glasswing, a partnership with software vendors to secure their critical software. This was followed shortly by OpenAI launching its invite-only “Trusted Access for Cyber” program, with both companies signaling that frontier AI models are starting to play a serious role in cybersecurity. To date, Mythos has identified thousands of zero-day vulnerabilities, including some over 10 years old.
In this first of a 2-part primer on LLM Cyber-offensive capabilities, we explore the key capabilities of Claude Mythos, and in Part 2, dive into the latest ArXiv research papers and Government studies to explain what these systems can do, where they fall short, and why it matters.
Part 1: The Cyber-Offensive Capabilities of LLMs
The Big Idea
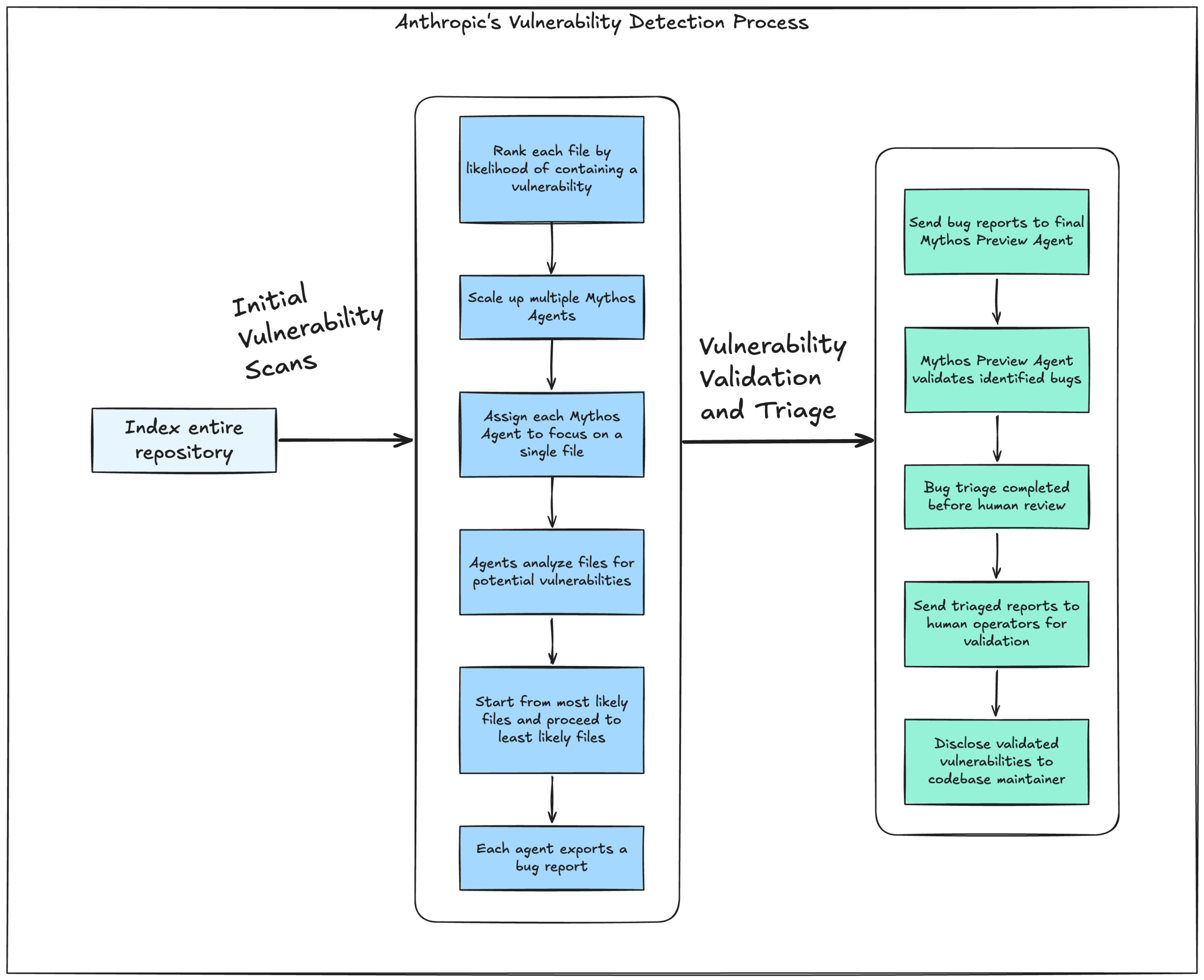
AI is getting much better at finding software weaknesses and turning them into working exploits. Anthropic’s researchers illustrate a process where they first index an entire repository and rank each file for it’s likelihood of containing a repository, then they scale up multiple instances of Mythos Agents, each of which is instructed to focus on a single file, looking for potential vulnerabilities, starting from the most likely files to the least, each agent exports a bug report, which is then sent to a final Mythos Preview Agent to validate the bugs identified. This way, each bug is first triaged, then sent to human operators for validation before being disclosed to the maintainer of the codebase.
The next step is exploit creation. Once a vulnerability is found, the model can sometimes build a working exploit that could let an attacker gain access, elevate privileges, or disrupt a system. Researchers say these exploits are sophisticated and chain together up to four vulnerabilities to create a functional exploit. The list of exploits can be found on this GitHub page: MAD Bugs (Vulnerabilities discovered and exploits developed entirely by AI).
Examples include:
- Remote Code Execution on FreeBSD using RPC requests, allowing an attacker to obtain complete control over the server
- Linux Kernel Privilege Escalation, allowing a restricted user to achieve complete root access on a server
- Web browser Just in Time (JIT) heap sprays that allow an attacker from one domain to read data from another domain (e.g., the victim’s bank)
- Bypassing certification authentication on common cryptography libraries (such as X509 certificate verification)
- Web Application Vulnerabilities including authentication bypasses and Denial of Service (DoS) attacks that allow attackers to impersonate users and remotely delete or crash services.
Why it matters
Mythos Preview was not specifically trained to have Cyber Offensive or Defensive capabilities. Anthropic’s researchers admit that this was a downstream consequence of general improvements in code, reasoning, and autonomy. The implication is that as AI models improve qualitatively, these cyber-offensive capabilities will become generally available.
Mythos Preview no longer works against traditional Security Benchmarks because it saturates them. Instead, researchers turned to zero-day vulnerabilities, which are bugs that were not previously known to exist.
The Defense In-Depth paradigm, which makes exploitation tedious rather than impossible, is no longer viable. For example, having multiple layers of security (Password, Multi-Factor Authentication Code, Network Security Monitoring) is designed so that if one fails, the others protect. However, when run at a large scale, language models grind through these tedious steps quickly.
We must revisit how we architect our defensive posture against potential AI systems. This includes adopting security governance standards (see my link to OpenCRE below), shortening our patch cycles, and also deploying LLMs in our vulnerability detection process (scroll down).
Key takeaways
Cybersecurity is no longer Human-speed. Testing has proven that models like ChatGPT 5.5 can solve a reverse-engineering task in 10 minutes at an API cost of $1.73, whereas an expert human would need approximately 12 hours using professional tooling.
While Project Glasswing (and its OpenAI counterpart) are currently invitation-only, there are several actions you can take today. This includes using existing generally available frontier models like Claude Opus 4.6 and GPT 5.5 to find vulnerabilities in your code. The recommended use cases for harnessing LLMS in your defensive posture (steps by Anthropic) are:
- Provide a first-round triage to evaluate the correctness and severity of bug reports.
- De-duplicate bug reports and otherwise help with the triage processes;
- Assist in writing reproduction steps for vulnerability reports.
- Write initial patch proposals for bug reports.
- Analyze cloud environments for misconfigurations.
- Aid engineers in reviewing pull requests for security bugs;
- Accelerate migrations from legacy systems to more secure ones;
The OWASP OpenCRE (Open Common Requirement Enumeration) project is a great starting point for orienting yourself to AI security standards and guidelines. It is a Cybersecurity Taxonomy which acts as a harmonized knowledge base that maps major AI Security standards, including NIST, MITRE ATLAS, ISO, OWASP, EU Agency for Cybersecurity (ENISA), BIML, and ETSI; and is under the oversight of the OWASP foundation.