In this installment of “I read research papers so you don’t have to!” (still written by humans!) Part 2 of our Primer on agentic AI Research exploring the innovations that got us this far, and what’s coming around the corner…
Part 1, introduced the world of AI Research in 2023 (click here to read more), and as we step into the future, 8 key advancement clusters of Agentic research have developed.
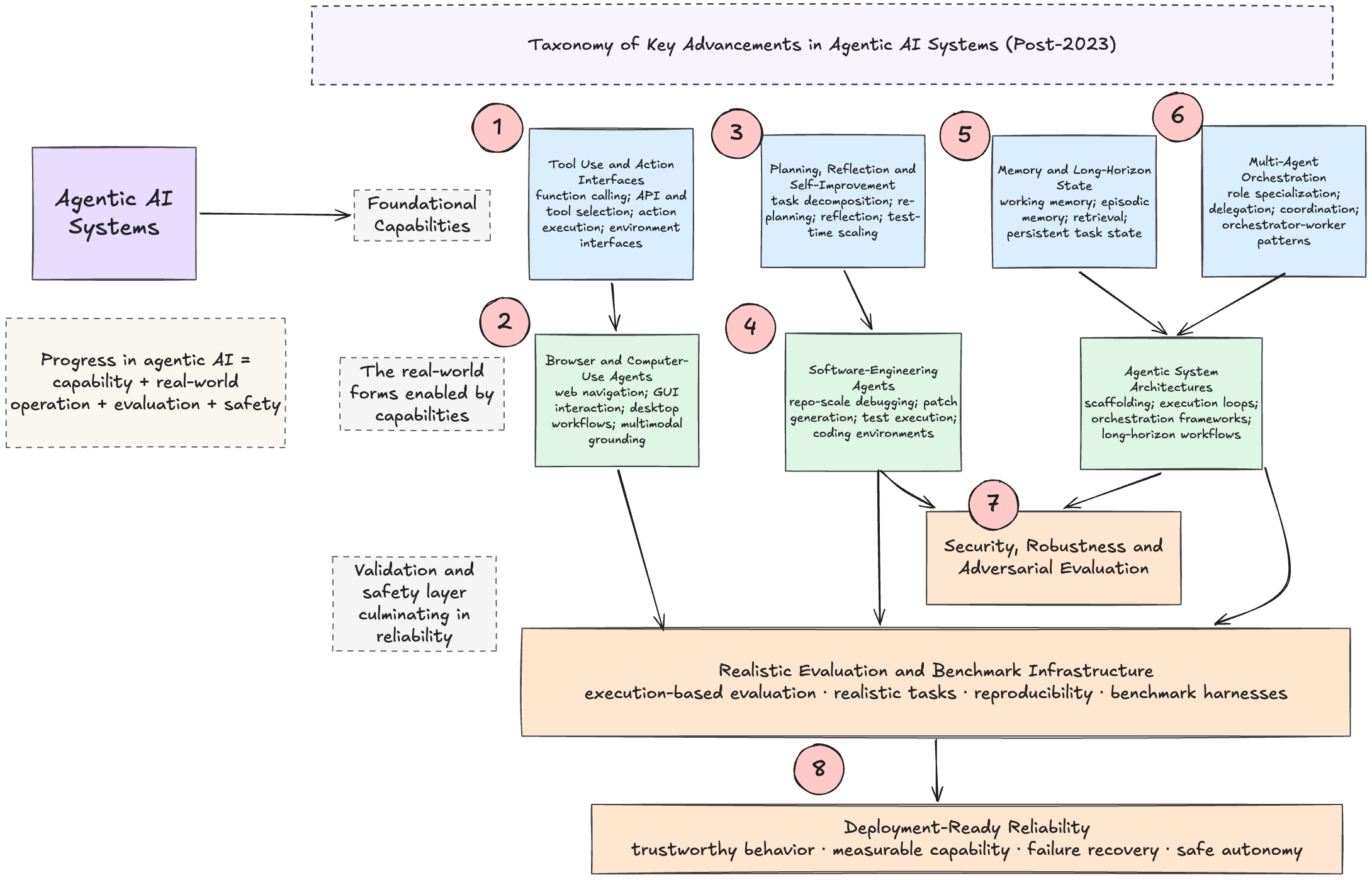
Area 1: Tool use and action interfaces
Significance: Tool use remains foundational, but the post-2023 consensus is that it is not just about choosing an API. It is about action schemas, function calling, environment interfaces, and reliable execution. The category matured from “can the model call a tool?” to “can an agent reliably choose, parameterize, sequence, and recover around tools in real workflows?”
Exemplar Papers:
- BFCL / Berkeley Function Calling Leaderboard (May 2023): The authors released Gorilla, a finetuned LLaMA-based model that excels at writing API calls, demonstrating an ability to hallucinate less. They also released APIBench, a comprehensive dataset consisting of HuggingFace, TorchHub, and TensorHub APIs.
- ToolACE (Sep 2024): This paper highlighted that a bottleneck for creating highly capable AI agents isn’t necessarily model size. It is the quality, complexity, and diversity of function-calling data. ToolACE features Self-Evolving API Diversity to dig through 26,507 diverse APIs across nearly 400 domains; Self-Guided Complexity, a Multi-Agent Simulation to ensure the generated training scenarios included hard tasks; and Dual-Layer Verification a ruthless verification system to make sure every single piece of generated training data.
- ToolLLM (Jul 2023): They introduce a general tool-use framework that excels at data construction, comprising API collection; instruction generation; and solution path annotation.
Area 2: Agents for Computer Use (ASU ) aka OS Agents
Significance: This is probably the single biggest practical shift since late 2023. Agents stopped being mostly text planners with tools and became systems that can operate web pages, desktops, and cross-application workflows through visual grounding and action loops. In current surveys, “agents for computer use” or “OS agents” is treated as a major subfield in its own right.
Exemplar Papers:
- OSWorld (Apr 2024): While other Benchmarks focus on the web, OSWorld spans entire operating systems, including Ubuntu, Windows, and macOS, requiring agents to handle file systems, desktop applications, and cross-app workflows,
- OmniACT (Feb 2024): OmniACT is a dataset and benchmark that extends beyond traditional web automation, covering a diverse range of desktop applications, such as “Play the next song”, and longer horizon tasks such as “Send an email to John Doe mentioning the time and place to meet”.
- OS Agent Survey (Jan 2025): This survey reviews 87 ACUs and 33 datasets, a clear sign of the significance of this dedicated category of agentic research.
Area 3: Planning, reflection, self-improvement, and test-time scaling
Significance: This is the conceptual line that runs from the early ReAct/Reflexion era into newer work on deliberate search, reflection, re-planning, recursive self-improvement, and spending more inference-time compute on agent tasks. The field now treats these as related attempts to make agents more robust over long trajectories rather than just smarter on one-shot prompts.
Exemplar Papers:
- Understanding the Planning of LLM Agents: A Survey (Feb 2024): This paperhighlighjts how planning developed into a specific taxonomy. It categorizes planning methods into task decomposition, plan selection, external modules, reflection, and memory.
- RISE aka Recursive IntroSpEction (Jul 2024): is an approach for fine-tuning LLMs by making LLM agents introspect upon their behavior, reasoning, and correcting their mistakes as more computation or interaction is available
- Large Language Models Can Self-Improve at Web Agent Tasks (2024): shows synthetic/self-improvement loops can materially improve web-agent performance.
- Benchmark Test-Time Scaling of General LLM Agents (Feb 2026): frames agent competence partly as a test-time compute/scaling problem.
- Reflexion (Mar 2023): Parameter Free learning is introduced through a novel framework to reinforce language agents not by updating weights, but instead through linguistic feedback.
Area 4: Software-engineering agents
Significance: Why this matters: coding became the first domain where agentic loops, tools, environment control, and benchmark harnesses all came together at scale. This area is important enough to stand on its own, rather than being merged into generic ACUs, because it developed a distinct ecosystem of repos, harnesses, patch validation, and leaderboard culture.
Exemplar Papers:
- SWE-Bench dataset (Oct 23): SWE-Bench comprises 2,294 real-world GitHub issues and their corresponding pull requests, collected from 12 widely used Python repositories. At time of release, the best-performing model, Claude 2, was able to solve only 1.96% of the issues.
- SWE-agent (May 24): Agent-computer interfaces were operationalized, enabling agentic debugging and patching at the repo-scale (scoring 12.5% on SWE-Bench).
- SWE-Bench verified (Aug 24): SWE-Bench Verified introduced human validation + containerized harnesses, which improves reliability.
- SWE-Bench+ (Oct 24): SWE-Bench had become a gold standard for verifying coding abilities in Agents. This paper was a reality check that highlighted benchmark pitfalls.
Area 5: Memory and long-horizon state management
Significance: After the 2023 survey, memory stopped being a vague “nice to have” and became a recognized bottleneck for long-running agents. Experts increasingly distinguish working memory, episodic memory, retrieval-based memory, and structured/causal memory, and there are now dedicated memory surveys and memory benchmarks.
Exemplar Papers:
- HiAgent (Aug 2024): This paper introduced a framework that leverages subgoals as memory chunks to manage the working memory of LLM-based agents hierarchically. LLMs can decide proactively to replace previous subgoals with summarized observations, retaining only the action-observation pairs relevant to the current subgoal.
- MemBench (Jun 2025): This benchmark evaluates the memory capability of LLM-based agents from multiple aspects, including their effectiveness, efficiency, and capacity by incorporating factual memory and reflective memory as different levels, and proposing participation and observation as various interactive scenarios.
- AMA-Bench aka Agent Memory with Any length (Feb 2026): This benchmark evaluates long-horizon memory for LLMs in real agentic applications. It features: (1) a set of real-world agentic trajectories across representative agentic applications, paired with expert-curated QA, and (2) a set of synthetic agentic trajectories that scale to arbitrary horizons, paired with rule-based QA.
Area 6: Multi-agent orchestration
Significance: since late 2023, the field has increasingly treated “one model + tools” and “multiple specialized agents with an orchestrator” as distinct design patterns. Whether or not multi-agent is always superior, it has become a mainstream architecture for decomposing long tasks, assigning roles, and mixing capabilities like browsing, code execution, and file operations.
Exemplar Papers:
- AutoGen Studio (Aug 2024): Microsoft introduced a No-Code Developer Tool for Building and Debugging Multi-Agent Systems, which helped standardize multi-agent construction and debugging workflows.
- Magentic-One (Nov 2024): This is a strong example of generalist multi-agent orchestration with a modular design that allows agents to be added or removed from the team without additional prompt tuning or training. It comprises an explicit Orchestrator and specialist agents.
- Multi-agent surveys (April 2024): Multiple surveys were released which show this became a research area in its own right.
Area 7: Security, robustness, and adversarial evaluation
Significance: Once agents began browsing, calling tools, storing memory, and acting in open environments, the community started treating prompt injection, tool misuse, memory poisoning, and unsafe action-taking as first-class research topics. This is now a standard pillar of agentic systems work.
Exemplar Papers:- InjecAgent (March 2024): This paper arose from a need to establish benchmarks to assess and mitigate the risks of indirect prompt injection (IPI) attacks, where malicious instructions are embedded within the content processed by LLMs, aiming to manipulate these agents into executing detrimental actions against users.
- Agent Security Bench aka ASB (May 2025): External tool and function calling by Agents introduced additional vulnerabilities. ASB is a comprehensive framework designed to evaluate the attacks and defenses of LLM-based agents, including 10 scenarios (e.g., e-commerce, autonomous driving, finance), over 400 tools, 27 attack/defense surfaces, and 7 evaluation metrics.
- WASP (May 2025): This benchmark for end-to-end evaluation of Web Agent Security against Prompt injection attacks demonstrates that top-tier AI models, including those with advanced reasoning capabilities, can be deceived by simple, low-effort human-written injections in very realistic scenarios.-
- ToolTweak (Oct 25): Tool selection and tool-use pipelines were recognized as attack surfaces (e.g., ToolTweak) rather than purely capability enablers
Area 8: Evaluation & observability instrumentation
Significance: This is a key aspect of development, given that agent progress is tightly coupled to benchmarks and harnesses. Agentic development moved toward execution-based, reproducible, increasingly realistic evaluations. The important shift was not just “more benchmarks,” but benchmarks that measure long-horizon action, side effects, multimodality, and real-world browsing/computer use. That makes this category the backbone for judging whether agent progress is genuine.
Exemplar Papers:
- General AI Assistance (GAIA) Nov 2023: A benchmark designed to evaluate AI systems on real-world tasks that are conceptually simple for humans but challenging for advanced artificial intelligence.
- VisualWebArena (Jan 2024): A benchmark designed to evaluate multimodal autonomous agents on realistic, visually grounded web tasks (Agents have to process visual informationto solve tasks)
- AssistantBench (Jul 2024): A benchmark designed to evaluate whether AI web agents can solve complex, multi-step tasks that would typically take a human several minutes to complete.
- BrowseComp (Apr 2025): aka “Browsing Competition” is a high-difficulty benchmark to measure an AI agent’s persistence and creativity in locating “hard-to-find, entangled information” on the live web.
- AutoGenBench (Nov 2024): Magentic-One is built on the AutoGen framework designed to solve complex, open-ended tasks by orchestrating a team of specialized agents. It comprises a hub-and-spoke model where a central Orchestrator manages four specialized agents: WebSurfer, Coder, ComputerTerminal, FileSurfer
Insight/So What?
As the field of LLM-based agents continues to evolve as a blistering pace, research has become more nuanced and specialized. At the end of the day, any taxonomy (including mine) is just a snapshot, like a map at the entrance to a shopping mall that helps you get oriented.