Paper’s name: Training language models to follow instructions with human feedback (arXiv:2203.02155, Mar 2022)
Where are the lead Authors now?
Long Ouyang, Research Scientist at OpenAI
Jeff Wu, AI researcher, Anthropic
Xu Jiang, Founder, Light Robotics
Diogo Almeida, Stealth Startup
Carroll L. Wainwright, Co-Founder, Metaculus
Pamela Mishkin, Member of Technical Staff, OpenAI
Paul Christiano, Head of Safety, Center for AI Standards and Innovation
Jan Leike, Member of Technical Staff at Anthropic
Ryan Lowe, Research Ecosystem Lead, Meaning Alignment Institute
The Problem It Solved
– Researchers found that scaling the number of parameters in Large language models (LLMs), did not reliably improve these model’s abilities to follow instructions, or improve model tendencies to generate harmful/toxic content, or “hallucinate” (confidently stated made-up facts).
– The paper focused on the problem of **Misalignment**, which essentially states that if most LLMs are trained to predict the next token on a web page from the internet, this is different from the objective “follow the user’s instructions helpfully and safely”. The misalignment exists between what the model is trained to output and what the user expects.
What’s It About?
– The alignment team at OpenAI introduced InstructGPT, a fine-tuned variant of GPT-3 with human feedback. This model was a key precursor to later instruction-following chat assistants.
– Outputs from these models trained with human feedback showed improvements in truthfulness and reductions in toxic output generation while experiencing minimal performance impacts
– They demonstrated that human testers preferred the outputs from InstructGPT, trained from just 1.3B parameters, compared to the 175B parameter GPT-3, which had over 100x more parameters.
Why It Matters (for Business)
– The cost of increasing model alignment is modest relative to model pretraining. For example, the Step-1 175B Supervised Fine-tuning (SFT) model requires 4.9 petaflops/s-days, and their refined Step-3 InstructGPT model requires 60 petaflops/s-days. In comparison, GPT-3 required 3,640 petaflops/s-days for training. This represents less than 2% of the total training cost to bring a model to production.
– Why does this matter? n a head-to-head comparison, 175B InstructGPT outputs were preferred to 175B GPT-3 outputs by human evaluators 85 ± 3% of the time, based on truthfulness, harmlessness and helpfulness.
Key TakeawaysInsight/So What?
– Fine-tuning large language models using human preferences significantly improves their behavior on a wide range of tasks
– Any kind of reinforcement learning or fine-tuning that involves a reward system ultimately aligns the model to provide responses that are aligned to labelers’ preferences influenced by the instructions they were given. And groups of labelers (humans) only agreed on the responses 73% of the time.
– That’s the point, humans aren’t aligned, so it’s going to be hard for models to be perfectly aligned with what a user deems as appropriate or harmful, but we can generalize based on cultures, geographies, and groups. That’s why the authors suggest training models that can be conditioned on the preferences of certain groups, or that can be easily fine-tuned or prompted to represent different groups. Different models can then be deployed and used by groups who endorse different values
Final thoughts
OpenAI released Chat-GPT in November 2022, and within 2 months, it had shot to over 100 million users. Running beneath the hood was a fine-tuned version of Chat-GPT 3.5, optimized for conversational dialogue using Reinforcement Learning with Human Feedback (RLHF).
InstructGPT, was crucial in popularizing and demonstrating the effectiveness of Reinforcement Learning from Human Feedback (RLHF) for aligning large language models (LLMs) with user intent, making them more helpful, honest, and harmless. While the core RLHF concept existed, this paper showed how to apply it in a practical, multi-stage process to create models that followed instructions better, even outperforming much larger base models like GPT-3
Link to full paper: https://arxiv.org/pdf/2203.02155
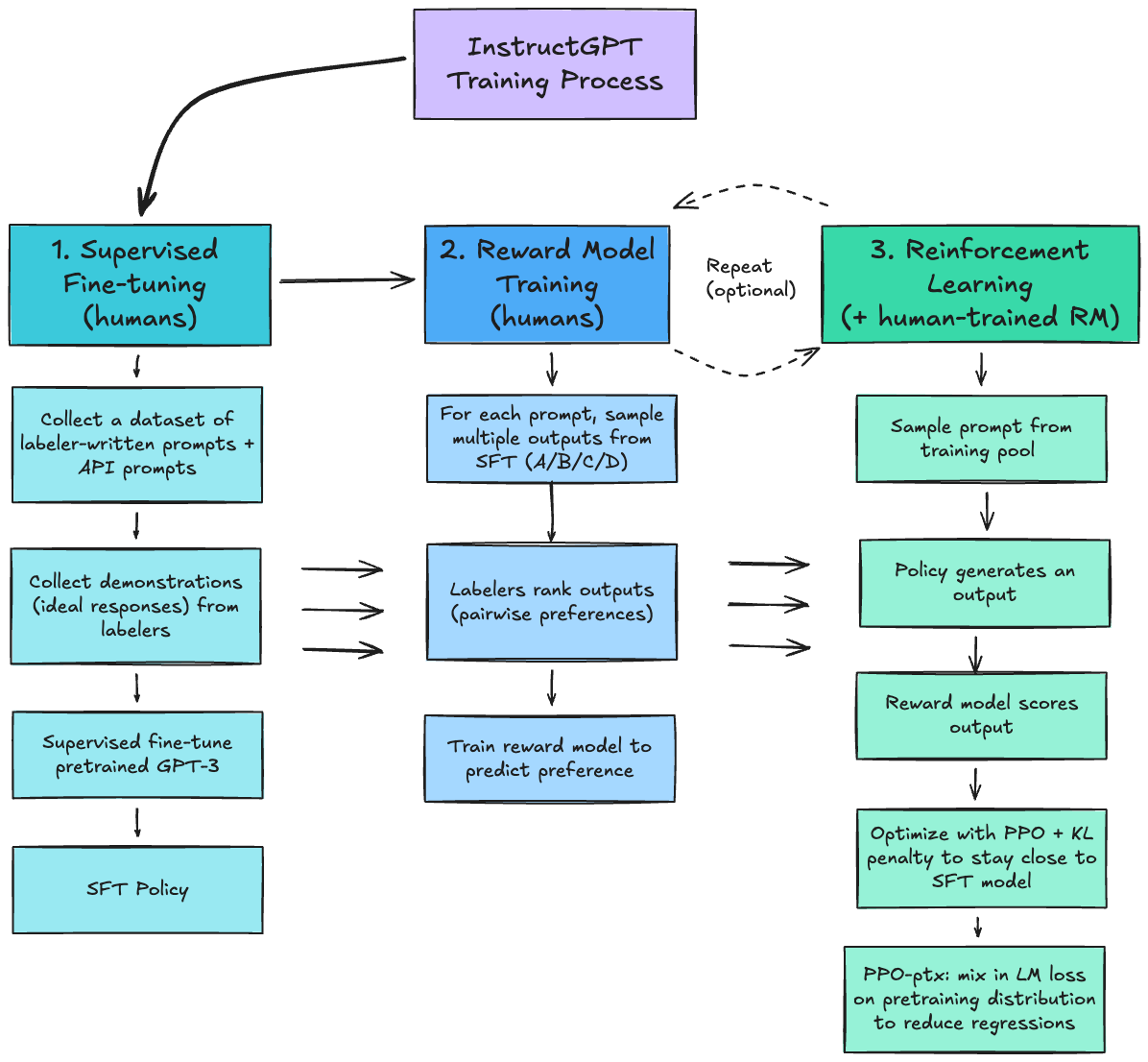
Footnote: InstructGPT training (simplified)
Step 1 Supervised Fine-Tuning (SFT): collect demonstrations, train a supervised policy
– Start with prompts from (a) labeler-written prompts and (b) prompts submitted via the OpenAI API. 
– Hire and screen a labeling team (team hired~40 contractors from Udemy and ScaleAI). 
– Collect human-written demonstrations of desired behavior on (mostly English) API prompts + some labeler-written prompts. 
– Fine-tune GPT-3 on these demonstrations using supervised learning (SFT). The paper reports training for 16 epochs with cosine LR decay and residual dropout 0.2.
Step 2 Reward Model (RM): collect preference rankings, train a reward predictor
– For each prompt, sample multiple model outputs and have labelers rank them. 
– Train a reward model to predict which output a labeler would prefer (pairwise preference / logistic “Bradley-Terry” style loss). 
– Architecture: start from the SFT model, remove the LM output head/unembedding, and train a scalar reward head. In this work they used 6B-parameter reward models. 
Step 3 Reinforcement learning (PPO): optimize the policy against the RM
– Use the RM as a reward function and fine-tune the SFT policy with PPO to maximize reward.
– Training is framed as a bandit environment: sample a customer prompt > generate a response > RM assigns reward > episode ends > update policy. 
– (Common detail) PPO typically includes a KL penalty to stay close to the SFT/reference model; the paper also uses PPO-ptx to reduce regressions.