In this second part on my series on influential AI papers, I’m going back to basics on the paper that kicked off the AI arms race, aka the GPT-3 paper
Paper’s Title: Language Models are Few-Shot Learners (Brown et. al., 2020)
Where are the lead Authors now?
Tom Brown – Co-Founder Anthropic [link](https://www.linkedin.com/in/nottombrown/)
Benjamin Mann – Co-Founder Anthropic [link](https://www.linkedin.com/in/benjamin-mann/)
Nick Ryder – VP, Research OpenAI [link](https://www.linkedin.com/in/nick-ryder-84774117b/)
Melanie Subbiah – PhD Candidate, Columbia Univ [link](https://www.linkedin.com/in/melanie-subbiah-7b702a8a/)
Jared Kaplan – Co-Founder Anthropic [link](https://www.linkedin.com/in/jared-kaplan-645843213/)
The Problem It Solved
- It was logistically difficult and also costly resource-wise to assemble a large supervised training dataset, use it to train a model for one specific task, and then repeat the process for every new task you wanted the model to perform.
- The problem with performing fine-tuning across multiple individual tasks risked building a model that is overly specific to the training distribution and does not generalize well outside it.
What’s It About?
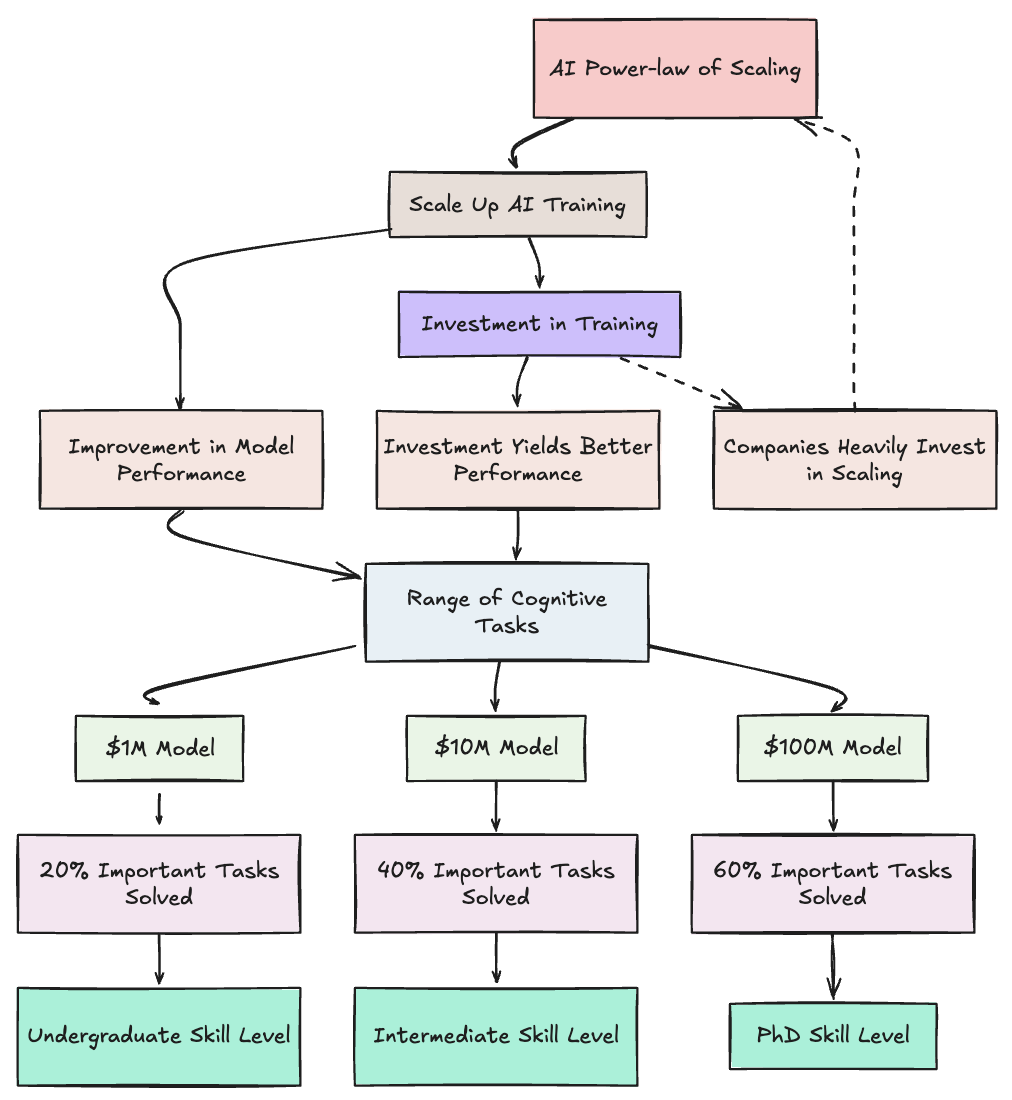
In this paper, the authors explain how they trained GPT-3 a 175 Bn parameter language model adapted from Google’s 2017 Transformer architecture. They demonstrated that GPT-3 could perform a wide range of tasks without gradient updates or fine-tuning, adhering to the AI power law which states that *..scaling up the training of AI systems leads to smoothly better results on a range of cognitive tasks, across the board* (Scaling Laws for Neural Language Models, OpenAI).
Why It Matters (for Business)
This paper outlined the key ingredients to building the AI we were all promised in the movies. You know, the ones that appeared to have ‘human-like’ responses and seemed to have some deeper level of intelligence. Like a modern no-fuss family cookbook, it spelled out instructions on how to take a generic language model built on transformer architecture, scale it up multiple orders of magnitude, and skip over the laborious step of task-specific fine-tuning. Then, fresh out of the oven, all you had to do was provide the model with instructions and a handful of examples in a prompt (known as few-shot prompting, and voila! The model could perform many different tasks!
Key Takeaways
- The conventional way to train a model to perform a task was by extensive pre-training on large corpus of text followed by task-specific fine-tuning using datasets of (potentially) hundreds of thousands of examples; and then repeat the process for every new task. The authors demonstrated it was possible to achieve results of similar quality by just scaling up a general model and skipping over fine-tuning altogether.
- This paper popularized the idea that LLMs can adapt on the fly via prompts, helping define the now‑standard practice of prompt engineering and evaluation via zero/one/few‑shot prompts.
Insight/So What?
This 2020 paper is an important continuation of OpenAI’s research efforts, namely their 2019 GPT-2 paper titled “Language Models are Unsupervised Multitask Learners”, and 2018’s original GPT paper titled “Improving Language Understanding by Generative Pre-Training”. These papers first established the Generative Pre-trained Transformer (GPT) model capable of achieving state of the art results by using generative pre-training and supervised fine-tuning; and subsequently demonstrated that models trained on a substantially large dataset could perform many tasks without the need to pre-train the model on each task.
Most importantly, it demonstrated how a model’s learning capability improves with scale. So to train a more powerful model, just throw more data inputs and more compute at it. This kicked off the current AI arms race for more compute resources, AI hyper-scaling and the race for more energy to power these models.
Link to full paper: https://arxiv.org/pdf/2005.14165