It’s time for our weekly dose of influential AI research papers. This time, a performance no-brainer… A subtle shift in prompting that can reap significant improvements at no additional costs!
Paper’s name: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (NeurIPS 2022; ArXiv:2201.11903v6)
Jason Wei, Research Scientist Meta
Xuezhi Wang, Senior Staff Research Scientist at Google DeepMind
Dale Schuurmans, Research Director at Google DeepMind
Maarten Bosma, Researcher & Principal Research Engineer, Microsoft AI
Brian Ichter, Co-Founder at Physical Intelligence
Fei Xia, Senior Staff Research Scientist at Google DeepMind
Ed H. Chi, VP of Research at Google DeepMind
Quoc V. Le, Research Scientist at Google
Denny Zhou, Research Scientist, Google DeepMind
The Problem It Solved
- Simply scaling up the size of language models was insufficient for challenging tasks like arithmetic, commonsense reasoning, and symbolic reasoning.
- Existing methods of improving responses either involved generating natural language rationales that lead to the final answer, which was costly and complicated to implement; or use in-context few-shot learning via prompting, i.e. “prompt” the model with a few input–output exemplars demonstrating the task, which tended to work poorly on tasks that require reasoning abilities
The Big Idea
- Chain of Thought (CoT): a series of intermediate reasoning steps significantly improves the ability of large language models to perform complex reasoning
- How it works: perform few-shot prompting for reasoning tasks, given a prompt that consists of triples: {input, chain of thought, output}
Why It Matters (for Business)
- This paper demonstrated that with a bit of prompt finessing, you could achieve State-of-the-Art accuracy that surpassed a fine-tuned GPT-3 model.
- This means that performance on complex tasks could often be improved without retraining, by changing prompts and evaluation harnesses. This helped lower iteration costs and reduce time-to-value for LLM pilots
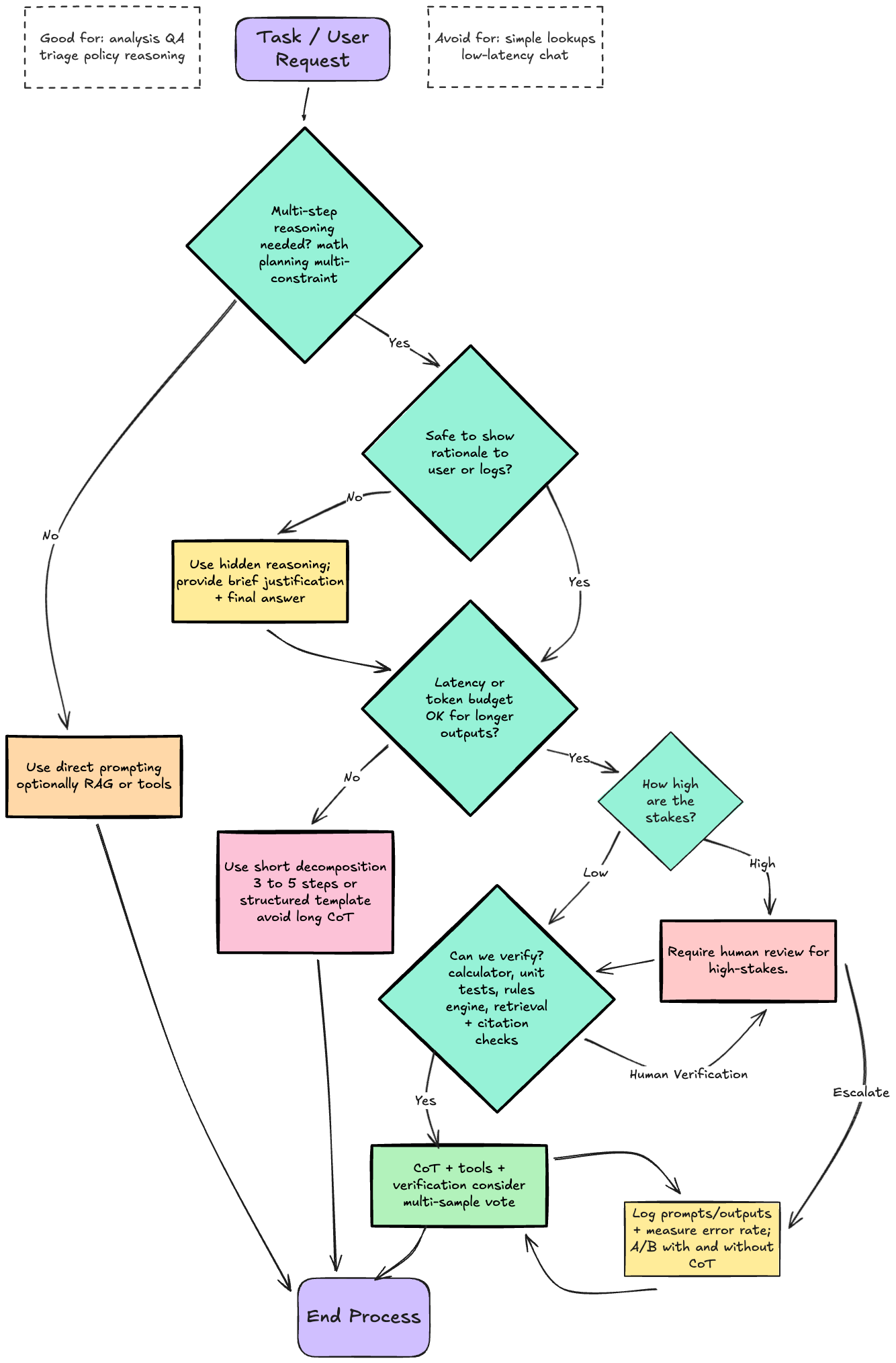
- CoT became a mainstream prompt-engineering primitive, to the point where vendors frequently include guidance on inducing step-by-step planning/chain-of-thought to improve output quality
- This is a discipline organizations can use to implement a lightweight prompt change, particularly for complex tasks that require multi-step reasoning.
Key Takeaways
- CoT prompting can unlock multi-step reasoning in sufficiently capable LLMs without fine-tuning, especially on tasks like math word problems, symbolic manipulation, and certain commonsense benchmarks.
- COT tends to work best when:
- the task genuinely requires intermediate steps (not just recall)
- the model is large/capable enough for reasoning to reliably emerge and you can verify outputs (tools, rules, tests, retrieval/citations)
- CoT inspired the following concepts that are in use today:
- Self-consistency, or the ability for a model to sense multiple reasoning paths and marginalize/majority-vote the most likely path
- Least-to-most prompting, where a sequence of simpler subproblems are solved before the full problem.
Insight/So What?
- This paper essentially reframed “prompting” from mere formatting into a capability-unlocking technique that produced significant performance gains.
- Use CoT prompting selectively for tasks where errors are expensive and reasoning depth matters (multi-step math/logic, policy checks, multi-constraint decisions), and measure the token-cost/latency impact explicitly in production.
Link to full paper: https://arxiv.org/pdf/2201.11903