Here is another foray into the world of large language model optimization, it’s all about quantization, folks!
Paper’s name: LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale (NeurIPS 2022; arXiv:2208.07339 11/22)
Where are the Authors now?
Tim Dettmers, Research Scientist Ai2
Mike Lewis, Pre-training Research Lead on the Llama team at Meta AI
Younes Belkada, Senior AI Engineer, Technology Innovation Institute
Luke Zettlemoyer, Research Manager, FAIR Seattle Site Lead at Meta AI
The Problem It Solved
– In 2022, running very large language models required a lot of expensive GPU memory just to use them (inference), even before you worry about training.
– Previous attempts to shrink models using a technique called quantization tended to hurt quality at larger scales or required extra tuning after training.
– This paper introduced LLM.int8(), a practical method that cuts the memory needed for inference roughly in half while keeping full‑precision quality. You could load a standard model, convert it and run it right away with fewer resources.
The Big Idea
– In big transformer models (around 6.7B parameters and up), most of the model’s size and most of its compute go into the large mixing steps, or the parts that think about each word in your prompt and then decide which other words to focus on to understand the whole sentence.
– The Authors found the real reason 8‑bit compression starts to break at that scale: specific outliers that are 20x larger than typical ones that show up across the almost the entire model.
– These outliers are rare but super important (~0.1% oof the model’s internal feature directions). If you set them to zero it’s like covering up the most critical words in a sentence. But if you erase the same number of features, it’s like crossing out a few letters in a long book: usually you still understand what the book is about.
– The LLM.Int8 function compresses LLMs by treating the super important features differently, it temporarily handles them in 16‑bit so they don’t get mangled by compression. This process uses quantization, similar to how you compress an image from a bitmap to a jpeg file.
Why It Matters (for Business)
– The LLM.Int8() function is an inference unlock: a highly cost effective way to deploy big models because model weights take about half the GPU memory compared to 16‑bit.
– The two ideas from the paper (vector-wise quantization + mixed‑precision decomposition for outliers) are still used today as the core of LLM.int8(), especially via the widely used bitsandbytes + Hugging Face Transformers integration
Key Takeaways
– The “cash burn” in LLM inference is where most parameters and compute live, and that’s exactly what LLM.int8() targets.
– Standard 8‑bit compression fails at scale because a few critical signals are much larger than everything else, so you need a method that protects those signals while compressing the rest.
– LLM.int8() uses 8‑bit for the bulk, 16‑bit for the outliers; preserving full‑precision results up to 175B parameters in their experiments.
Insight/So What?
– Model’s to big to fit on hardware? Use LLM.int8() and now you can deploy!
– Budget constrained by hefty inference fees? Use LLM.int8() to use fewer or smaller GPUs for the same model!
– How much less?
– A 16-bit quantized version of OPT-175B required 8 x Nvidia A100 GPUs (80GB RAM). That’s $15k per card in 2022, ~ $150k per server.
– By quantizing the same model down to 8-bits, the same model could run with 8 x Nvidia RTX 3090 GPUs (24GB RAM), costing $1k per card, or about $15k for the whole rig.
– That’s a whopping 10x reduction in compute costs!
Extra: How does the 2-part quantization procedure (LLM.int8()) work?
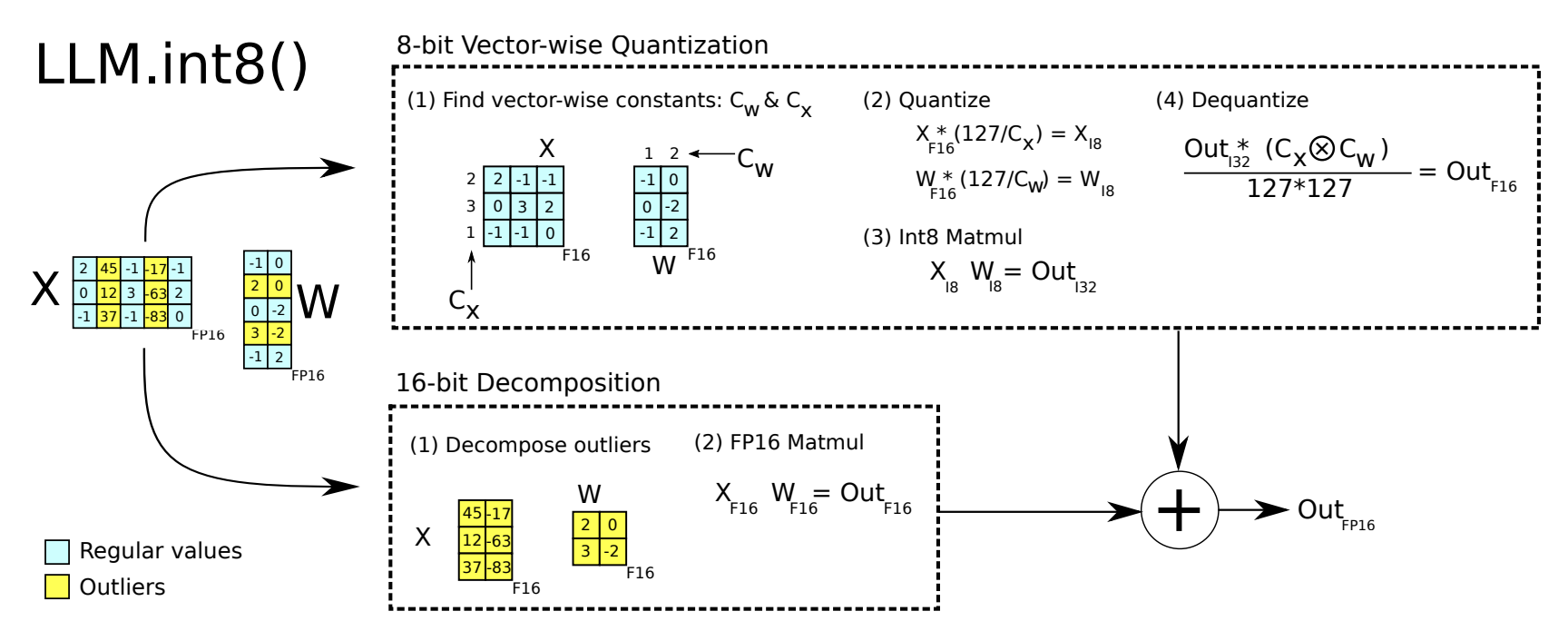
– Vector-wise quantization: View matrix multiplication as a sequence of independent inner products. Assign a different scaling constant cxf16 to each row of input matrix and cw to each column of weight matrix
Mixed-precision decomposition: 16-bit matrix multiplication for the outlier feature dimensions (0.1%) and 8-bit matrix multiplication for the other 99.9% of the dimensions
Important Caveats
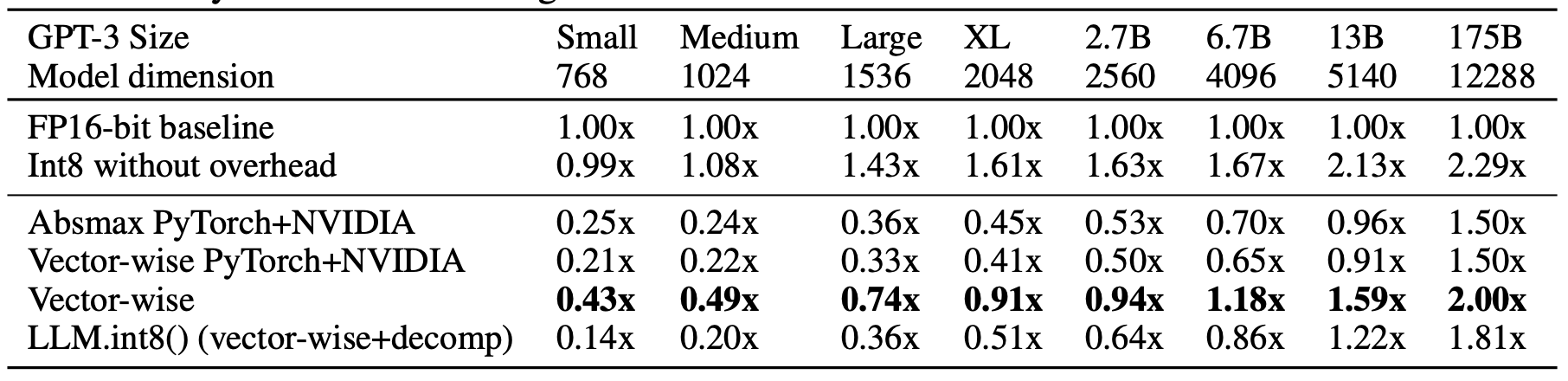
– 6.7B params is an important threshold. At below 6.7B, large features (columns) with magnitudes up to 20x larger than in other dimensions first appear in about 25% of all transformer layers. At around 6.7B parameters, a phase shift occurs, and all transformer layers and 75% of all sequence dimensions are affected by extreme magnitude features.
– Quantization and decomposition overhead is significant, and Int8 matrix multiplication itself only yields an advantage if the entire GPU is well saturated, which is only true for large matrix multiplication. This occurs only in LLMs with a model dimension of 4096 or larger.
– Models with model size 2560 or smaller are slowed down. Adding mixed precision decomposition slows inference further so that only the 13B and 175B models have speedups.
Link to full paper
Other links/presentations:
Presentation at Machine Learning Tokyo (MLT _init_)
Great video of Tim on 8-bit optimizations