Paper’s name: Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity (arXiv:2101.03961v3) 6/2022
Where are the lead Authors now?
William (Liam) Fedus, Co-Founder of Periodic Labs
Barret Zoph, rejoined OpenAI from Thinking Machines Lab
Noam Shazeer, VP Engineering, Gemini Co-lead, Google
The Problem It Solved
- Prior attempts had been made to “split up” calculations across multiple processor cores, but this increased complexity, costs and introduced training instability (ie some experts getting too much work, others are idle)
- The authors refined this process through a simple switch routing mechanism, they could effectively scale the amount of compute across a neural network by adding more compute nodes (in this case Google’s TPU core processors).
- This allowed scaling upwards of Trillion parameter models.
What’s It About?
To understand the significance of this innovation, we need to understand Mixture of Experts (MoE) models
So how does the Switch Transformer work?
- This is an example of a sparse model, where only a subset of their parameters for each example and are compute efficient (standard “dense” models use every parameter for each example during training)
- We take the standard architecture of a Transformer (see image) and swap out the Feed Forward Network layer and swap it out with a distributed network, powered by a router which intelligently passes tokens selectively to the most appropriate compute nodes (aka Experts) for processing
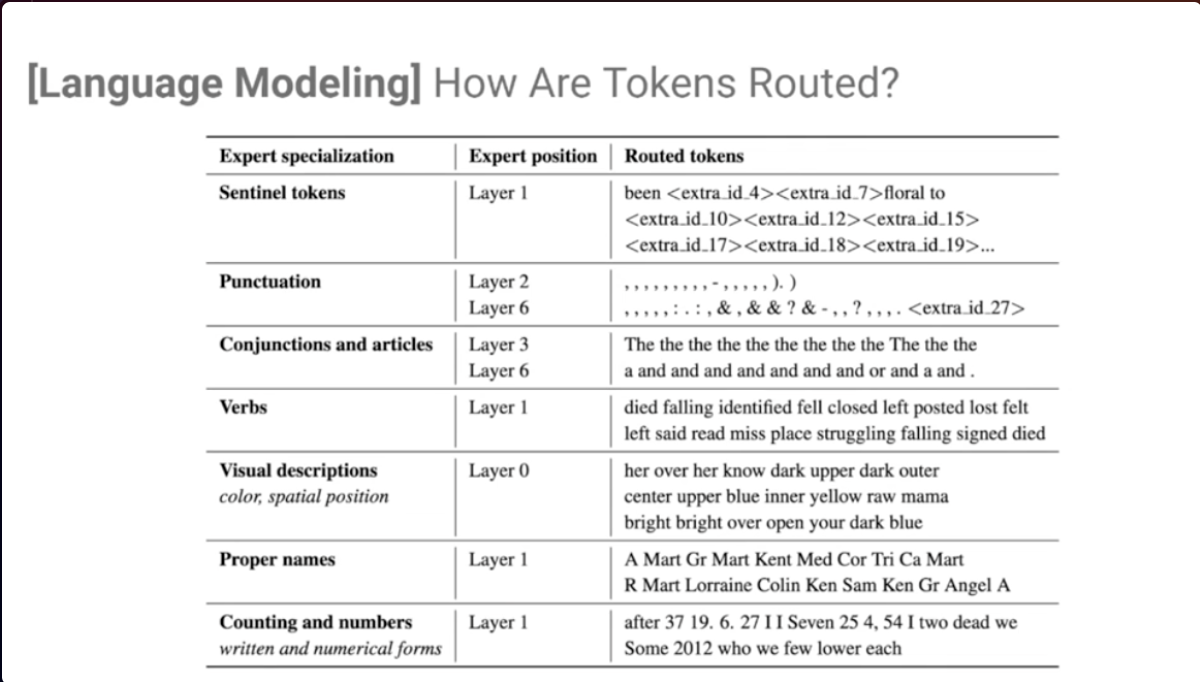
- An expert is a layer or node that is specialized at performing certain tasks.
- For example in Natural Language Processing, you might have an expert that is good at understanding punctuation, another at understanding verbs; and yet another at visual descriptions; and another at counting and numbers, and so on. As a token (a bunch of words or characters) passes through the neural network, the most suitable expert(s) will pick up the token for processing.
– Note: The following isn’t part of a Switch Transformer, however it’s useful to understand other examples of Experts. The second image below illustrates how different experts exist in a neural network specifically trained for image recognition (Mustafa et al. 2022). Some experts are really good at detecting body parts (like eyes), and others at textures, or the food

Why It Matters (for Business)
- Mixture of Experts is a core architectural concept implemented by leading OpenSource LLMs like Kimi-K2, DeepSeek-V3, Mixtral 8x7B, and also Commercial models like GPT-4, and Gemini
- A computationally-matched dense model is outpaced by its Switch (sparse) counterpart. In other words, you don’t need such a big dense model if you can architect a sparse distributed model with many experts, it takes less time to train and can train on a much smaller sample of data, and yet consumes just as many resources at run-time
- Cloud providers like Amazon Sagemaker supports MoE through AWS Elastic Fabric Adapter (EFA) and P5 instances; Microsoft Azure supports DeepSpeed-MoE with NDm A100 v4 VMs and InfiniBand networking; GCP Vertex AL all handle the high-bandwidth requirements of training large MoE models.
Key Takeaways
The authors added a fourth axis to Power law scaling for LLMs new total: model size, data set size, computational budget, parameter count. When keeping the FLOPS per token fixed, having more parameters (experts) speeds up training. Increasing the number of experts leads to more sample efficient models
- Pre-training: training time is significantly reduced
- Fine-tuning: fine-tuning is dramatically improved, outperforming larger dense models while using 1/20th of the compute
- Inference: Sparse models demonstrate greater accuracy with fewer compute cycles (FLOPs) per token for zero- and few-shot performance
- Calibration: Sparse expert models seem to know that they don’t know the answer to a prompt, better than dense models
Insight/So What?
This paper has a practical contribution and a philosophical one , fancy!
- Prior to this innovation there was a rule that if you wanted to increase the number of parameters in your model (hence higher quality outputs), you had to increase the amount of processing, resulting in higher cost. By demonstrating through a simple switch routing mechanism that routed tokens to a single expert (k=1) rather than multiple experts, you could keep the costs constant, they broke the power scaling rule! This was a landmark moment in AI, when LLMs finally harnessed cheap distributed compute in training massive neural networks through parallelization > scaling models up to 1.6T parameters!
- I love this paper, because behind all the math and reasoning, this paper holds a deeper meaning. Liam, Barrett and Noam followed their intuition that the scaling law (aka more power equals more compute) could be broken and they did it! That’s what scientific discovery is all about!
References:
Link to full paper
Youtube video of Liam and Barrett presenting findings