Time for another installment of influential research papers that set the stage for the AI revolution. This week, it’s all about a way to augment and enhance your LLM with up to date, context relevant data without needing to go through pre-training all over again.
Paper Title: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (Lewis, et. al. 2020)
Where are the lead Authors now?
Patrick Lewis, Staff Data Scientist, Meta
Ethan Perez, Research Scientist, Anthropic
Patrick Lewis, Staff Data Scientist, Meta
Ethan Perez, Research Scientist, Anthropic
Aleksandra Piktus, Member of Technical Staff, Cohere
Fabio Petroni, Group Leader, EMBL
Vladimir Karpukhin, Staff Software Engineer, Google
Naman Goyal, ML Engineer, Google Deepmind
Heinrich Küttler, Member of the Technical Team, XAI
Mike Lewis, Research Scientist, Meta AI
Wen-tau Yih, Research Scientist, Meta
Tim Rocktäschel, Director/Principal Scientist, Google Deepmind
Sebastian Riedel, Research Scientist, Google Deepmind
Douwe Kiela, CEO/CoFounder Contextual AI
The Problem It Solved
- At the time of writing (May 2020), it was well understood that major language models could learn substantial amount of in-depth knowledge from data during pre-training.
- However, these models lacked up to date knowledge of the world beyond their knowledge cut-off date. Imagine your LLM is a super intelligent assistant, however they’re locked in a bubble and unable to access more recent knowledge.
- Initially these models were primarily used for research, so current data wasn’t as relevant, but as LLM’s garnered widespread adoption, this lack of current knowledge became a major concern, with models often hallucinating (aka lying confidently) about events or facts.
What’s It About?
- The authors proposed a method of augmenting language models by using non-parametric or retrieval-based memory. In essence, they introduced a fine-tuning approach where models could now access both parametric (the data the model was originally trained on) and non-parametric memory (a more up to date repository of information).
- This allowed models to revise and expand their knowledge, and the accessed knowledge can be inspected and interpretedPlain-language explanation of the core innovation
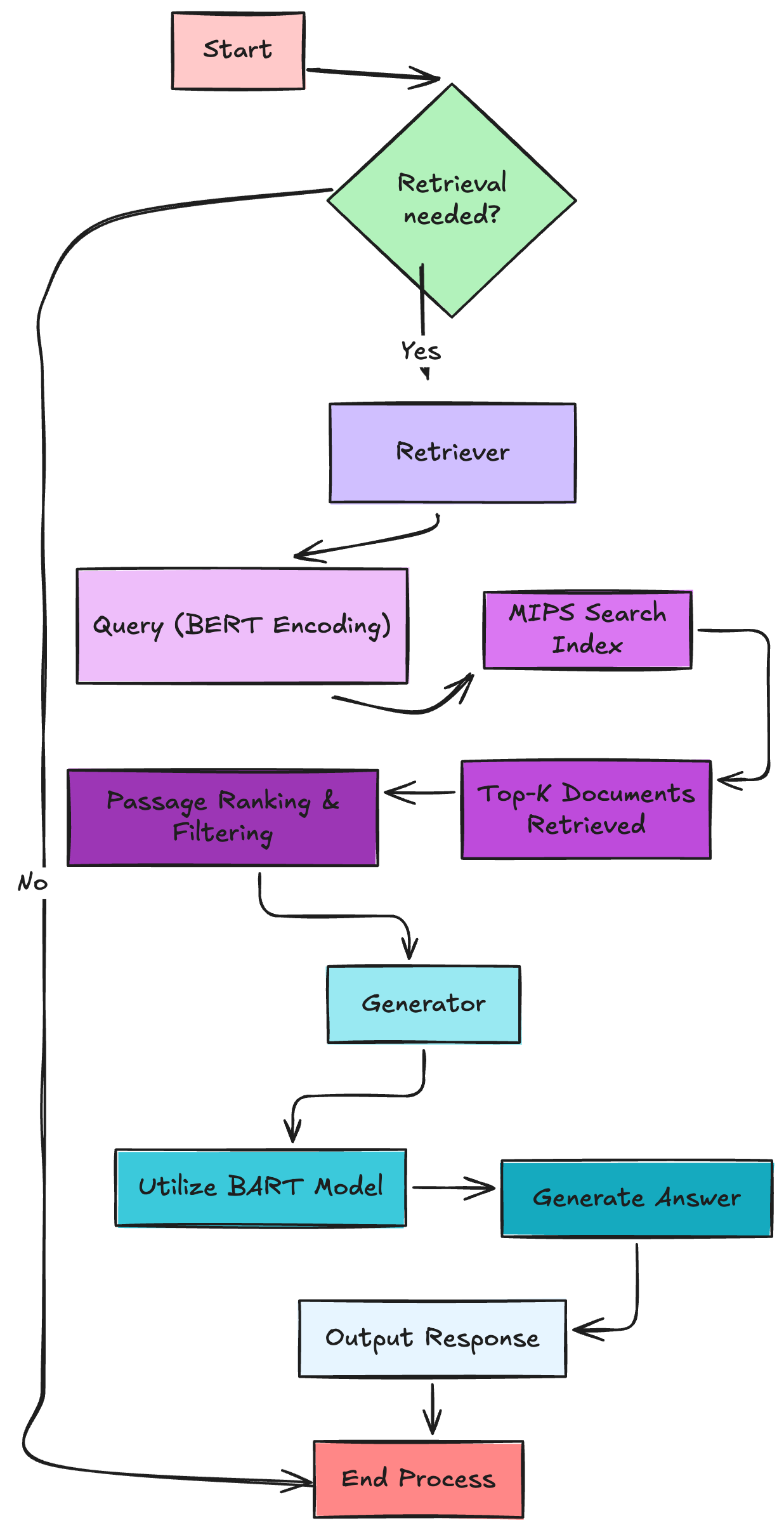
- The RAG solution comprises of two key components, the Retriever, and the Generator. The Retriever works like a librarian who’s purpose is to find the most relevant information needed to answer a question. The Generator’s job is to take the information obtained by the retriever and format it or synthesize it into a well structured answer.
- For the retriever, the authors loaded a complete dump of Wikipedia into their non-parametric memory, then they split up the data into 100-word chunks, resulting in over 21 million documents. Then they built a search index by encoding each chunk of data using a BERTBASE encoder. This embedding was trained to retrieve documents which contain answers to specific sets of trivia and natural questions.
- For the generator, the authors used a. special type of transformer model called BART, an autoregressive sequence to sequence (seq2seq) generator. Autoregressive simply means that each new token generated depends on all previously generated tokens plus the encoder’s context.
- After performing unsupervised training, they demonstrated State of the Art (SotA)-level performance when generating specific and factually accurate responses compared to other cutting edge models.
- Critically, they also found that the document encoder could be kept fixed during training and only fine-tuning performed on the query encoder (used by the retriever) and the generator.
Why It Matters (for Business)
- This finding allowed LLMs to “step out” of their bubbles and serve accurate and relevant information about customers and users, by simply updating the data store the RAG is trained on (such as a company knowledge base or customer database). This was much easier to do than retraining the entire model from scratch.
- This paved the way for large-scale Enterprise B2B and B2C applications for RAG.
Key Takeaways(Bulleted list)
- Open-Domain Question Answering: RAG set a new State of the Art standard by combining the generation flexibility of the “closed-book” (parametric-only) approaches and the performance of “open-book” retrieval-based approaches
- RAG Architecture: Both parametric and non-parametric memories work together. The non-parametric component helps to guide the generation, drawing out specific knowledge stored in the parametric memory
- Fewer Hallucinations: RAG models hallucinate less and generate factually correct text more often than prevailing language models.
- Easy to train and maintain: RAG performance scores are within 4.3% of SotA models, which are complex pipeline systems with domain-specific architectures and substantial engineering, trained using intermediate retrieval supervision, which RAG does not require.
Insight/So What?
META is seen as a laggard in the AI race, but that’s far from true. This paper also highlights the nature of cross-pollination and dispersal of talent in the top-most echelons of the AI industry. Many of the authors of this paper went on to important roles at Google’s Deepmind, Anthropic, XAI and the European Molecular Biology Laboratory (EMBL)
Link to full paper: https://arxiv.org/abs/2005.11401