I read influential AI research papers so you don’t have to!
WHY? As an AI practitioner, I frequently found myself rushing into implementations, however I always longed for a deeper understanding of the theory and concepts. After 4 years of PhD training and reading hundreds of research papers (and publishing a few of my own), I’ve structured each paper in an easy to digest way.
As always, if you think this is valuable, or have a paper/topic you’d like me to write about, please repost or leave a comment!
Title: Attention Is All You Need (2017)
Authors (Affiliation at the time):
Google Brain: Ashish Vaswani, Noam Shazeer, Łukasz Kaiser, Aidan N. Gomez
Google Research: Niki Parmar, Jakob Uszkoreit, Illia Polosukhin, Llion Jones
Link to full paper: Arxiv
The Problem It Solved
The state-of-the-art deep learning algorithms at the time were difficult to parallelize and contemporary hardware (like GPUs and TPUs) which were designed for massive parallel computation.
- Recurrent Neural Networks (RNNs) essentially process inputs over multiple sequential steps, taking outputs from one step and passing them into the next, which means you can’t begin the next step until the current one has completed. Another dominant architecture at the time, Convolutional Neural Networks (CNNs), which are still used today for image processing, could split up a large image into many sections (known as positions) and process each one, looking for specific patterns, however trying to detect a pattern across distant parts of the same image required some fancy footwork to stack multiple layers over the data, so this limited parallelization too.
- RNNs also ran into issues with sufficiently long sequences of inputs, where during model training, there was a tendency for the models to overstep their bounds when multiplying through the same model weights multiple times, though a process known as Back Propagation Through Time (BPTT). You can read up on the problem of Vanishing gradients and Exploding gradients [here](https://www.ibm.com/think/topics/gradient-descent#Challenges+with+gradient+descent). Workarounds like Long Short Term Memory (LSTM) and Gated Recurrent Units (GRUs) had some success, but the fundamental problem of RNNs, having to work sequentially, made them difficult to parallelize.
- Some variants of RNNs work by compressing an entire input sequence into a single fixed-size context vector (called the initial hidden state). This is part of a common process in Neural Networks called embedding, where an input sequence (like a sentence or pixels of an image) is mapped and encoded into a learned vector representation that captures semantic meaning. The decoder then uses this embedding to generate an output sequence. The challenge with embeddings is that the compression process discards some of the input data, which may be critical data. This represents a loss in fidelity.
What’s It About?
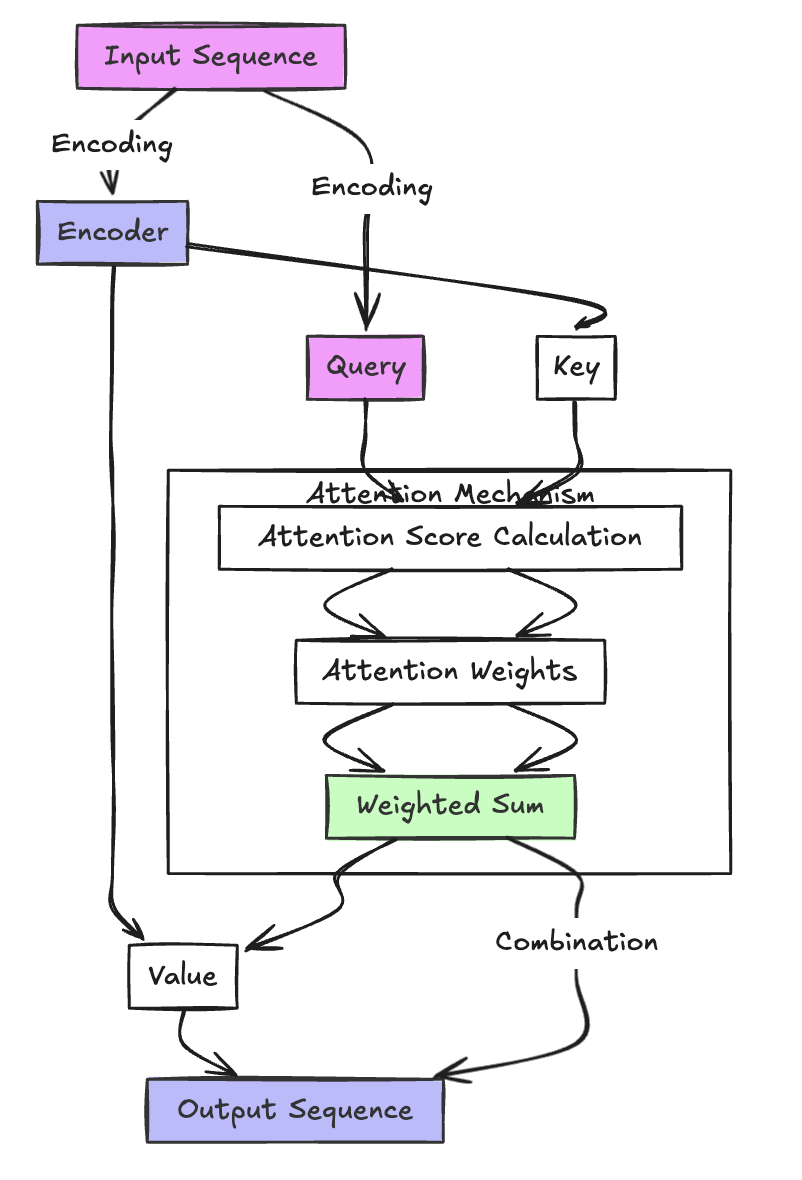
The authors proposed Transformer architecture, which supported more parallelization and was inherently less costly to train. Transformers avoided recurrent and convolutional layers, instead using multi-layered self-attention, which uses positional encodings that essentially act as a directional indicator, and helps the model understand the relative and absolute positions of each input within the sequence. The decoder can use the positional encodings to access the full input representation at each decoding step rather than relying on a single compressed summary.
This translates to shorter path lengths: Path lengths are essentially how many steps a piece of information has to traverse the network to affect something else. For RNNs, if the first word in a sentence needs to influence the last word, that information must be passed step by step through every position in between, so the path is long. The authors state that the maximum path length in RNNs is O(n), where n is the sequence length. For transformers, any word can look directly at any other word in a single attention step, so the path is very short—just one hop between any two positions, or O(1).
Why It Matters (for Business)
Training Efficiency and Speed: The computing rig the authors used to train the models used in the paper comprised of a single machine equipped with 8 NVIDIA P100 GPUs, at a cost of approximately $50k (in $2017 dollars), a relatively modest computing cost, and a fraction of the time it took to train competing architectures at the time (just 12 hours to train their base model and 3.5 days for their big model), vs days to weeks to train RNN models.
Scalability: Transformers supported greater parallelization by eliminating dependencies on recurrence for sequential processing, thus they could scale to larger datasets far more efficiently than traditional models.
Key Takeaways
- Transformers combined the benefits of parallelization of CNNs and the direct long-range dependency modeling of attention mechanisms by shortening the effective path length between distant tokens compared with CNNs, improving the ability to learn long-range dependencies; and eliminating sequential computation over time steps (like RNNs), allowing constant-depth paths between any two positions and full parallelization over sequence length.
- This enabled the breakthrough of models to reach the scale of modern large language models and multi-modal systems built on transformer foundations.
Insight/So What?
They’ve been harshly criticized in the past, but Google did the world a favor by releasing this innovation to the world. Far from being left in the dust, I call Google a fast follower, as their flagship Gemini 3.0 model (released just around the time of this posting) is proving to be one of the most advanced and capable models of all time.
Link to Paper: https://arxiv.org/abs/1706.03762